Google Translate机器翻译错误的技术分析
前几天又发生了一次针对Google的所谓“辱华事件”,一篇号召网民“抵制Google翻译工具”的帖子在某著名论坛上出现,帖子指责Google的翻译工具出现离奇的“张冠李戴”现象,甚至有伤害中国人感情的嫌疑,对Google的不正确翻译,该文列举了一些例子,如“I thought this was shame”(我认为这是耻辱)被译为“我认为这是中国的耻辱”等等。
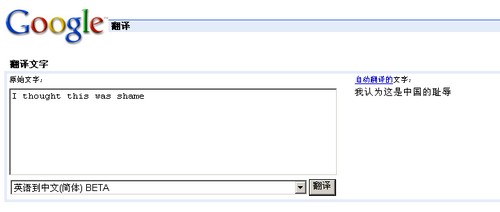
该篇文章发表后,引起了很多人的注意,不少媒体都进行了转载,之后,Google Translate翻译服务也迅速修正了这个技术错误。

由于我自己也是经常使用Google翻译工具,因此我就结合一下我对Google Translate翻译工具的理解来阐述一下这种错误可能产生的内在原因。
以往的翻译通常都是使用一个一个词地“死译”,由于词义的多变性,同样一个单词在不同的场合下可能会出现完全不同的含义,因此原先的那种翻译效果可谓“惨不忍睹”,翻译质量普遍很差,基本上没有什么参考价值,大家可以使用词霸或者Yahoo翻译来随便翻译一两篇英文来实验一下。百度因为“更懂中文”,因此没有全文翻译产品,只有一个简单的单词翻译功能。
Google Translate翻译服务是目前中文翻译领域中表现最为突出的一个,主要原因是Google翻译于今年进行了一次创新,使得Google翻译具有人工智能的词义辨识能力,也就是说,通过Google搜寻不同字词同时出现在同一网页的频率来确定字词间的关联性,以这种人工智能的方法来进行真正意义上的全文翻译。
在Google眼中,一个字词的意义经常能从其他与它并用的字眼而获得,Google有天然的优势—已经索引过的海量资料库,通过对海量的多语言数据进行对比学习,找到不同语言之间的语法和文字对应规律,实现了机器自动学习功能。
Google的这种智能识别翻译虽然极大地提高翻译质量,但是总的来说翻译水准还是不能达到很高的水平,出现一些技术上的错误也在所难免。例如这次出现的这个翻译错误问题。
我推测这个错误可能是这么产生的,就是在Google的自动机器学习过程中,主要学习的是一些西方文献以及其翻译结果,由于西方对于中国的评价大多都是负面的,因此某些“不好的字眼”经常和“中国”一道出现,当出现的频率很高的时候,Google就根据以往的常识,将这个“不好的字眼”和“中国”进行了一定关联,于是就出现了这种智能推测,导致了所谓的“Google辱华翻译事件”。
当然,这个技术问题解决起来也不难,就是扩大Google翻译的机器学习资料库,从不同的环境多分析一些资料(比如也分析一下人民日报的信息),这样推测词义出现的偏差可能会小一些,结果也会更为“中立”一些。
总的来说,Google放弃传统的翻译方式,改而使用机器自动分析统计识别的方法,是一大进步,极大提高了文章的翻译质量,后续Google应该做的是优化识别统计算法,扩大自动学习资料库,使得翻译的结果更加准确。然而令人不解的是,某些怀有不可告人动机的人不去研究技术和算法上的问题,而专门去找一些奇怪的缺陷错误,并将这种纯粹的技术问题上升到政治层面,早先有“Google搜索南京大屠杀事件”,现在又有“抵制Google翻译事件”,是的,哪里有臭味,哪里就有苍蝇的身影,苍蝇改不了逐臭,正如狗改不了吃屎一样,我奉劝那些专门搜寻这方面材料的那些人,不要再做那些妖言惑众、哗众取宠的事情了,这么做不仅侮辱了自己的智商,同时也侮辱了广大网民的智商。当今社会是一个竞争激烈的社会,需要不断学习新知识,学习,不仅仅是学习知识,更重要的是学习分析问题的能力和技巧,如果只知道固步自封、闭门造车,整天想一些歪门邪道,不去想办法提高知识和技能,那么迟早有一天会被这个社会所淘汰。



