入围今年IROS最佳论文:交互行为下的无人车自适应策略
内容来自将门机器人主题社群
作者:胡冶萍
公众号/将门创投
关于作者:胡冶萍,加州大学伯克利分校 (UC Berkeley) 机械工程专业的第四年博士生,导师为Masayoshi Tomizuka。她的研究方向是无人车的行为预测、决策和轨迹规划。读博期间曾获得IEEE Intelligent Vehicles Symposium (IV)最佳学生论文奖,并入围今年IROS的最佳论文奖的评选。

更多信息可访问她的个人主页: https://yeping-hu.github.io
背景介绍
目前的无人车驾驶系统配备了很多自动驾驶功能, 比如自动跟车, 自动泊车,等等。但即便如此,无人车依旧无法真正拥有像人类一样的驾驶行为。想达到这一目标,最关键的一步就是让无人车学会如何和其他车辆进行交互。而无可避免的一个需要交互的场景就是道路交汇(e.g. 上匝道), 我们列举了四个不同的道路交汇场景如下图:红车代表的是自动驾驶汽车。
注意在(a),(b)场景中,两条交汇道路的路权不同。在路权较低的道路上行驶的汽车需要一定程度地避让行驶在另一路权较高道路上的汽车。

那么如果把一辆目前市面上技术最先进的自动驾驶汽车放到以上环境中去,它会怎么办呢?我们基本可以确定它会采取最保守的驾驶策略:
如果想要上匝道,它会停下直到另一道路上没有车或者其他车距离自己非常远的时候才会选择上匝道。即使两条交汇道路路权相同(e.g.场景(c) ), 当前的无人车系统也同样会选择避让其他车,直到它认为足够安全才会继续前行。很显然,这样的驾驶策略在车流密集的情况下是完全不适用的,如果完全依赖当前的无人车系统,想要成功上匝道也许要等到地老天荒。
解决哪些问题
想要解决此类交互问题,我们首先要了解面对的难点究竟是什么。以下列举了我们认为目前需要解决的三个点:
1. 现实生活中,不同的司机有不同的驾驶行为:比如有的司机会有意识地”帮助”想要上匝道的车辆,而有的司机则不会。所以想要让无人车可以和路上拥有任意驾驶行为的车进行交互,是有难度的。
2. 想要设计出一个可以应用在交互场景中,具有鲁棒性的决策算法,我们需要其他车辆的驾驶模型去不断测试并且矫正现有的算法。但悲伤的是,我们并不能准确地知道且构建出这些模型。所以这变成了一个“鸡生蛋,蛋生鸡”的哲学性问题。
3. 目前现有的处理交汇道路上的决策算法通常只限于单一场景,单一路权规则,而且无法很好地处理道路上的不同车流量和车辆行为的情况。
为了解决以上问题,在这篇文章中,我们提出了一个可以自适应的自动驾驶策略,用于处理无人车在交互行为中的决策问题。我们的算法基于多智能体强化学习(Multi-agent Reinforcement Learning),旨在让无人车在与其它车交互的过程中,间接判断出其它车辆不同的驾驶行为, 并且根据它们不同的cooperativeness,以及当前道路规则,对自己的驾驶策略实时做出改变,从而可以成功且有效地应对不同的道路交汇场景。
具体解决方法
「接下来提到的算法涉及马尔科夫模型和actor-critic的一些知识,可以参考论文中前提知识介绍的章节。」
在我们提出的算法中,存在一个可以表现出不同驾驶行为以及可以采取自适应策略的actor,以及一对decentralize和centralize的critic。Decentralized critic 希望让拥有不同驾驶风格的智能体学习到如何在不考虑交互,以及完全遵守交通规则的情况下,应对多种交汇道路。而 centralized critic 则鼓励智能体之间的交互,并且在交互过程中不造成交通拥堵等负面影响。
为了使我们的actor和两个critic达到我们想要的效果,我们利用了curriculum learning的思想,提出了两个阶段的训练策略。我们在第一和第二个训练阶段中,把智能体依次放入”robot world”和“intelligent world”的两个不同的环境,使其可以阶段性地学习,从而最终达理想的结果。在两个环境下的算法具体结构如下图:

在这里是policy的参数,和分别表示decentralized和centralized critic想要让policy Π 更新的梯度表示policy整体更新的梯度。
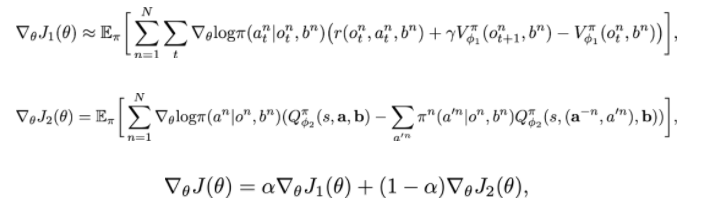
实验设计及结果
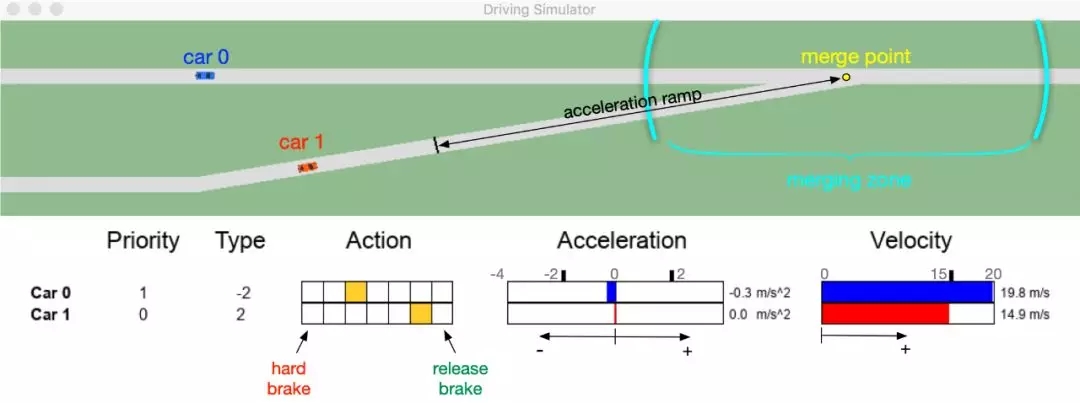
实验环境:我们自己开发了一个模拟的驾驶环境,专门用于道路交汇场景。在这个驾驶环境中,我们可以任意定义道路的路权,车辆个数,车辆的驾驶行为,以及车辆的初始状态等。这给我们的交汇场景提供了足够的随机性。
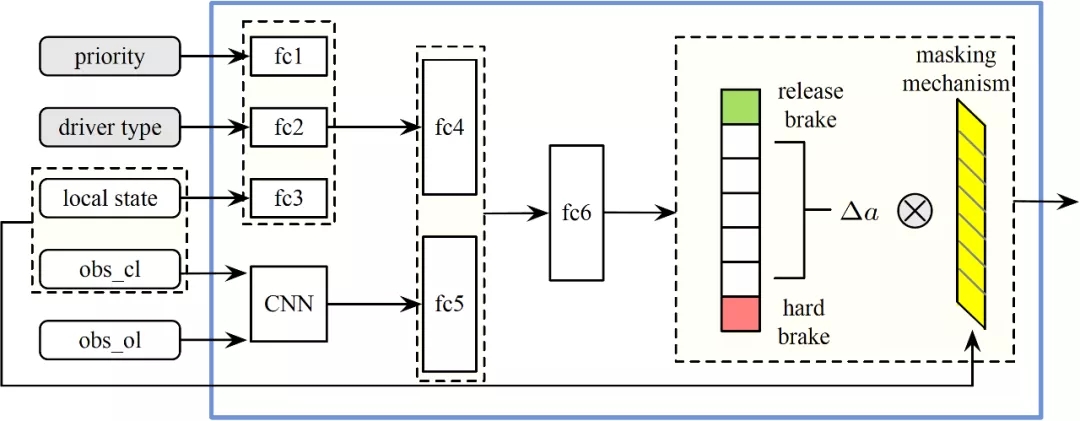
策略网络(policy network):我们的策略网络如下图所示,值得一提的是,不同于以往的定义方法,我们把车辆的决策输出定义为加速度的变化量。这样我们便可以把低维度的离散action space转化为连续的加速度action输入到控制器中。同时,为了提高训练的效率,我们还加入了masking mechanism。具体输入和输出信息请参考论文。
实验结果:我们把无人车(红车)放到了不同场景下进行测试,其余的蓝色车辆有着和红车一样的策略网络,但由于路权等信息的不同,它们均有不同的驾驶策略,而且它们的策略均会根据情况进行实时改变。在这里,我们的无人车并不知道其它车辆的策略,所以无人车需要通过当前道路情况,以及和车辆的交互情况,做出合理的决策。
下图是三个不同的场景,在图(a)中,两辆车距交汇点的距离几乎一样,两辆车一开始都试探性地减了一点速,但是由于蓝车具有较高路权,而且减速幅度并不大,所以无人车做出判断,选择让蓝车先过。图(b)中,虽然无人车路权较低,但由于两辆蓝车的空隙相对比较大,无人车判断可以安全在两车之间汇入,所以选择直接加速。而图(c)中车流密度相对较大,无人车便选择等待。有趣的是,图(c)中的这三辆蓝车在有较高路权的情况下,依然会在邻近交汇点时选择轻踩油门,以防万一,这和人类开车时的行为很接近。

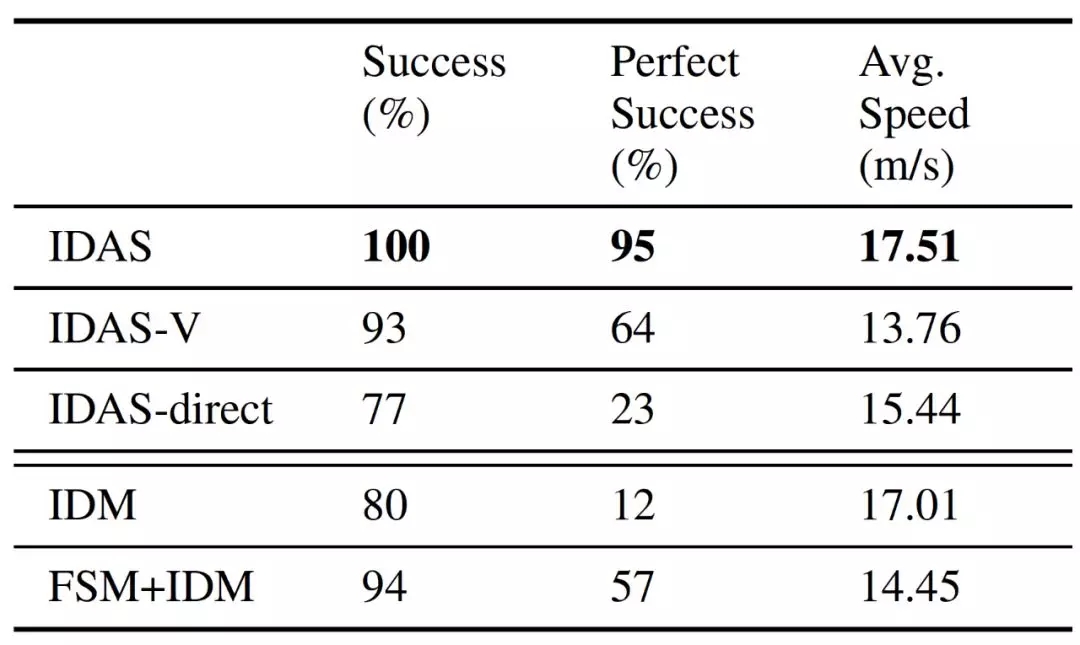
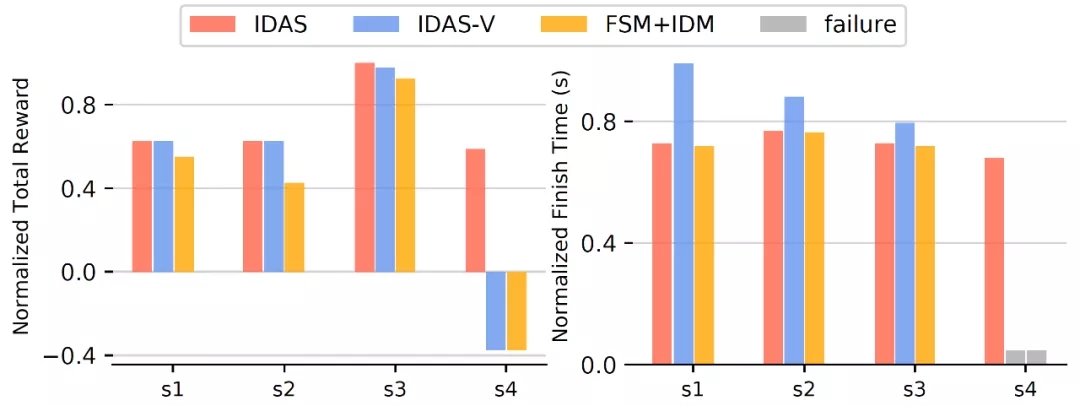
我们将提出的算法进行了量化的对比和评估,结果如下: 在表中可以到看我们的算法(IDAS) 在不同交汇场景的测试中可以让无人车以较高的平均速度达到100%的成功率。这说明在保障安全的情况下,我们的无人车策略可以使其不再是过于保守地等待,而是主动和其他车辆进行交互,从而寻求高效地完成道路交汇任务。
更多实验结果和算法细节可参见论文和相关视频:
https://arxiv.org/pdf/1904.06025.pdf
https://youtu.be/2CTTFHDW1ec